DevOps, más allá de la tecnología (parte II) – Los principios del flujo

En la adopción de DevOps es importante considerar los siguientes principios:

A continuación, profundizaremos en los principios de flujo:
“En el flujo de valor de la tecnología, el trabajo generalmente fluye desde Negocio Desarrollo Operaciones Clientes. The First Way requiere un flujo de trabajo rápido y fluido desde el desarrollo hasta la operación, para entregar valor a los clientes rápidamente”

Hacer visible el flujo
A diferencia de un flujo en una fábrica, los flujos de TI son mucho más complejos, esto hace necesario incrementar los esfuerzos para generar un flujo continuo.

En una fábrica, fácilmente se puede detectar un problema en flujo, porque visiblemente se puede ver si hay material acumulándose en un centro de trabajo. En los flujos de tecnología esto no ocurre de esta manera, los flujos son muy dinámicos y tan sólo con un clic, se puede redireccionar un producto para ser trabajado por otro centro de trabajo.
Una forma de hacer visibles estos flujos de TI es utilizando otra herramienta que surgió de la industria automotriz, los tableros Kanban.
Al colocar todo el trabajo para cada centro en colas y hacerlo visible, todos los interesados pueden priorizar más fácilmente el trabajo en el contexto de objetivos globales. Hacer esto permite que cada centro de trabajo realice una sola tarea con la mayor prioridad hasta que se complete, aumentando el rendimiento.
Limitar el trabajo en progreso (WIP – Work In Progress)
El límite del trabajo en progreso (WIP) restringe la cantidad máxima de elementos de trabajo en las diferentes etapas (columnas del tablero Kanban) del flujo de trabajo.

Controlar el tamaño de la cola [WIP] es una herramienta de administración extremadamente poderosa, ya que es uno de los pocos indicadores principales sobre el cual tenemos un grado de control, con la mayoría de los elementos de trabajo, no sabemos cuánto tiempo tomará hasta que se complete realmente.
A continuación, vemos un ejemplo gráfico sobre cómo impacta el resultado al definir un WIP de 3 ó 1. El WIP es la cantidad de elementos que voy a tener en una columna de un tablero Kanban.
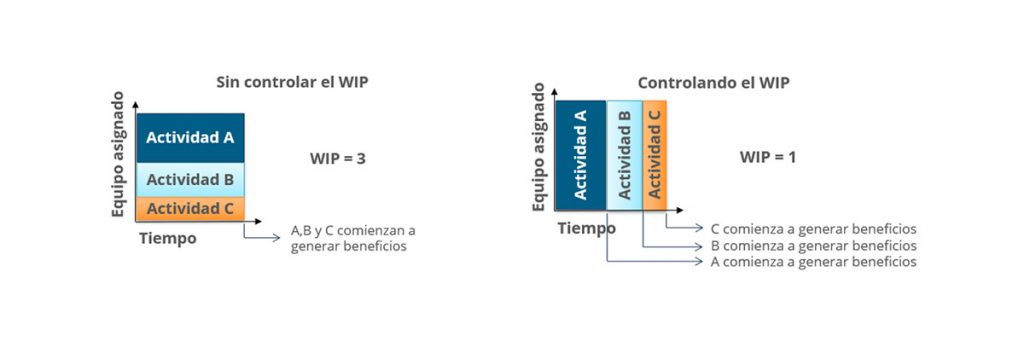
Por la simplicidad de este ejemplo, se puede pensar que mientras menor es el WIP es mejor, pero esto no siempre es así, a veces el ritmo óptimo de un flujo de trabajo puede requerir configurar diferentes niveles de WIP para lograr un flujo continuo. La búsqueda de este punto excelente de trabajo es una de las principales tareas que deben abordar los equipos de desarrollo.
Reducir el tamaño de los lotes
El tamaño del lote es la unidad en la que los productos de trabajo se mueven entre etapas en un proceso de desarrollo (o DevOps). Para el software, el lote más fácil de ver es el código. Cada vez que un ingeniero hace “commit” de sus cambios, está definiendo un lote de trabajo.
Existen muchas técnicas para controlar estos lotes, que van desde los pequeños lotes necesarios para la implementación continua hasta el desarrollo más tradicional basado en “branches”, donde todo el código de varios desarrolladores que trabajan durante semanas o meses se agrupa e integra en conjunto.
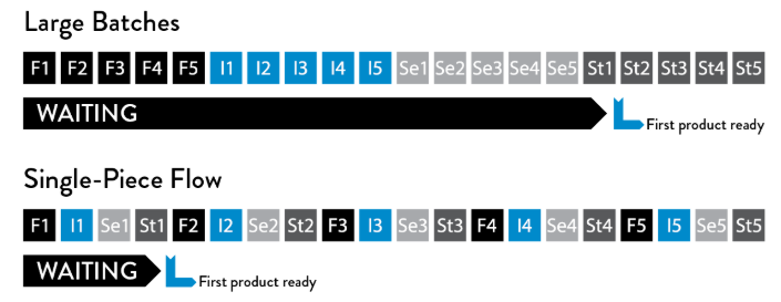
Supongamos el siguiente ejemplo, tenemos diez folletos para enviar por correo y cada uno requiere cuatro pasos: doblar el papel, insertar el papel en el sobre, cerrar el sobre y sellar el sobre.
La estrategia de lote grande sería realizar una operación secuencialmente en cada uno de los diez folletos.
Por otro lado, en la estrategia de lotes pequeños, es decir, “flujo de una sola pieza”, todos los pasos necesarios para completar cada folleto se realizan de forma secuencial antes de comenzar con el siguiente. En otras palabras, doblamos una hoja de papel, la insertamos en el sobre, lo cerramos y la estampamos; solo entonces comenzamos el proceso con la siguiente hoja de papel.
Reducir la cantidad de “pasamanos”
En el flujo de valor de la tecnología, cada vez que tenemos largos plazos de implementación, medidos en meses, a menudo se debe a que se requieren cientos de operaciones para mover nuestro código del control de versiones al entorno de producción.
Cada uno de estos pasos es una potencial cola de espera, donde el trabajo esperará cuando dependamos de los recursos que se comparten entre diferentes flujos de valor (por ejemplo, en operaciones centralizadas). Los plazos de entrega de estas solicitudes suelen ser tan largos que existe una escalada constante para que el trabajo se realice dentro de los plazos necesarios.
Para mitigar este tipo de problemas, se debe procurar reducir el número de traspasos, ya sea automatizando porciones significativas del trabajo o reorganizando equipos para que puedan entregar valor al cliente en lugar de depender constantemente de otros.

Aumentamos el flujo al reducir la cantidad de tiempo que nuestro trabajo pasa esperando en la cola, así como la cantidad de tiempo sin valor agregado.
Levantar restricciones
Para reducir los tiempos de entrega y aumentar el rendimiento, necesitamos identificar continuamente las limitaciones de nuestro sistema y mejorar su capacidad de trabajo.

“En cualquier flujo de valor, siempre hay una dirección de flujo, y siempre hay una única restricción; cualquier mejora que no se haga con esa restricción es una ilusión.”
Beyond the Goal, el Dr. GoldratT
El desempeño óptimo de un sistema, en este caso el flujo de valor, NO es la suma de sus optimizaciones locales. Aumentar la fortaleza de cualquier otro elemento que no sea el eslabón más débil no tiene impacto real en la capacidad del sistema. En el caso de la figura, una mejora de 20 Kg en el eslabón amarillo, no aumenta en 20 Kg la capacidad de carga del sistema, sino sólo en 10 Kg. Esto se da porque una vez que hemos levantado una restricción, la misma se ha movido a otra parte del sistema (eslabón verde). Se logra optimizar el sistema a través de una serie de iteraciones de mejora, monitoreando las restricciones y levantándolas continuamente.
Eliminar dificultades y desperdicios del flujo
Shigeo Shingo, uno de los pioneros del sistema de producción de Toyota, creía que los desechos constituían la mayor amenaza para la viabilidad del Negocio. En la actualidad se han establecido las siguientes categorías de desperdicios y dificultades.

- Trabajo parcialmente realizado: Esto incluye cualquier trabajo en el flujo de valor que no se haya completado (por ejemplo, documentos de requisitos u órdenes de cambio aún no revisados) y el trabajo que está en la cola (por ejemplo, esperando la revisión de control de calidad o el ticket de administrador del servidor). El trabajo parcialmente realizado se vuelve obsoleto y pierde valor a medida que pasa el tiempo.
- Procesos adicionales: cualquier trabajo adicional que se realice en un proceso que no agregue valor al cliente. Esto puede incluir documentación no utilizada en un centro de trabajo posterior, o revisiones o aprobaciones que no agreguen valor a la salida. Los procesos adicionales agregan esfuerzo y aumentan los plazos de entrega.
- Funciones adicionales: funciones integradas en el servicio que no son necesarias para la organización o el cliente. Las características adicionales agregan complejidad y esfuerzo a las pruebas y a la administración de la funcionalidad.
- Cambio de tareas: cuando las personas son asignadas a múltiples proyectos y flujos de valor, requiriendo cambiar de contexto y administrar dependencias entre los trabajos, agregando esfuerzo y tiempo adicionales al flujo de valor.
- En espera: cualquier retraso en el trabajo producto de la espera de recursos necesarios para que puedan completar el trabajo actual. Los retrasos aumentan el tiempo del ciclo y evitan que el cliente obtenga valor.
- Movimiento: la cantidad de esfuerzo para mover información o materiales de un centro de trabajo a otro. El desperdicio de movimiento se puede crear cuando es necesario comunicarse con ciertas personas y frecuentemente no son fáciles de ubicar. Las transferencias de personas o recursos también crean desperdicio de movimiento y, a menudo, requieren comunicación adicional para resolver ambigüedades.
- Defectos: la información, los materiales o los productos incorrectos, faltantes o poco claros crean desperdicio, ya que se necesita un esfuerzo para resolver estos problemas. Cuanto más tiempo transcurra entre la creación y la detección del defecto, más difícil será resolverlo.
- Trabajo no estándar o manual: confianza en el trabajo no estándar o manual de otros, como el uso de servidores que no respetan la configuración establecida o accesos no otorgados oportunamente. Idealmente, cualquier dependencia de las Operaciones debe ser automatizada, tender al autoservicio y disponible a demanda.
- Actos heroicos: para que una organización logre objetivos, las personas y los equipos se colocan en una posición en la que deben realizar actos irrazonables, que incluso pueden convertirse en parte de su trabajo diario (por ejemplo, problemas nocturnos de producción a las 2:00 a.m., creando cientos de tickets de trabajo como parte de cada lanzamiento de software). A veces los actos heroicos son necesarios, pero cuando se vuelven parte de la rutina diaria introducen una entropía muy grande al flujo de desarrollo llevándolo a un círculo vicioso: más actos heroicos para corregir defectos productos del desgaste que producen los mismos actos heroicos.
Artículos relacionados
En SOAINT, comprendemos tus contextos organizacionales, con el fin de construir realidades tecnológicas encaminadas a tu desarrollo y crecimiento.
¡Confía en nosotros para desarrollar todo el potencial de tu empresa!


