DevOps, más allá de la tecnología (parte III) – Los principios del feedback

En la adopción de DevOps es importante considerar los siguientes principios:

A continuación, profundizaremos en los principios del feedback:
“Este camino que debemos recorrer describe los principios que permiten la retroalimentación recíproca rápida y constante de izquierda a derecha en todas las etapas del flujo de valor. Nuestro objetivo es crear un sistema de trabajo cada vez más seguro y resiliente.”
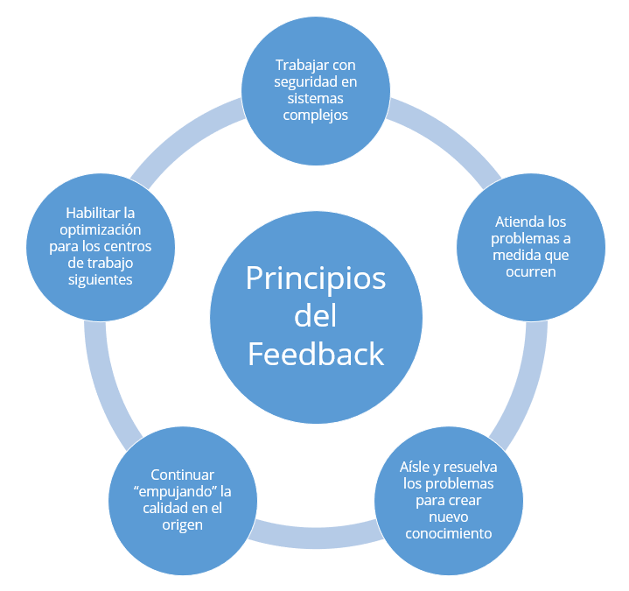
Trabajar con seguridad con sistemas complejos
Una de las características definitorias de un sistema complejo es que desafía la capacidad de cualquier persona para ver el sistema en su conjunto y comprender cómo encajan todas las piezas. Los sistemas complejos suelen tener un alto grado de interconexión de componentes estrechamente acoplados, y el comportamiento a nivel del sistema no puede explicarse simplemente en términos del comportamiento de los componentes del sistema.

Otra característica de los sistemas complejos es que, hacer lo mismo dos veces no conducirá de manera predecible o necesariamente al mismo resultado. Esta característica hace que las listas de verificación estáticas y las “mejores prácticas” sean valiosas pero insuficientes para evitar que ocurran catástrofes.
Para trabajar con sistemas complejos de una manera segura se deben dar las siguientes condiciones:
- El trabajo complejo se gestiona de modo que se evidencien los problemas de diseño y operaciones. Un ingrediente clave es generar el clima de confianza que permite crear flujos de comunicación de los problemas existentes.
- Los problemas se aíslan y resuelven, lo que resulta en la construcción rápida de nuevos conocimientos.
- El nuevo conocimiento local se explota globalmente en toda la organización.
- Los líderes crean otros líderes que continuamente desarrollan este tipo de capacidades.
Atienda los problemas a medida que ocurren
En un sistema de trabajo seguro, debemos probar constantemente nuestros supuestos de diseño y operación. Nuestro objetivo es aumentar el flujo de información en nuestro sistema considerando la mayor cantidad de áreas posible, antes, más rápido, más barato y con la mayor claridad entre causa y efecto. Cuantos más supuestos podamos invalidar, más rápido podremos encontrar y solucionar problemas, aumentando nuestra capacidad de recuperación, agilidad y capacidad de aprender e innovar.
En el flujo de valor de la tecnología, a menudo obtenemos malos resultados debido a la ausencia de retroalimentación rápida. Por ejemplo, en un proyecto de software en cascada, podemos desarrollar código durante todo un año y no obtener comentarios sobre la calidad hasta que comencemos la fase de prueba, o peor, cuando lancemos nuestro software a los clientes. Cuando la retroalimentación es tan tardía e infrecuente, es demasiado lento para permitirnos prevenir resultados no deseados.
Atender los problemas a medida que ocurren es una buena medida contra la entropía en sistemas complejos. Pero es importante una aclaración, es común confundir la aplicación de un “workarounds” con la solución de problema. En este caso, sólo estamos generando deuda técnica y una falsa imagen de “problema solucionado”. El feedback, además de rápido, debe ser sincero.
Aísle y resuelva los problemas para crear conocimiento
Obviamente, no es suficiente detectar simplemente cuando ocurre algo inesperado. Cuando ocurren problemas, debemos aislarlos y analizarlos, movilizando a quien sea necesario para resolver el problema.
En lugar trabajar alrededor del problema (workaround) o programar una solución “cuando tengamos más tiempo”, nos apresuramos a solucionarlo de inmediato. Los beneficios de esta forma de trabajo son:
- Evita que el problema progrese aguas abajo, donde el costo y el esfuerzo para repararlo aumenta exponencialmente y genera deuda técnica.
- Impide que el centro de trabajo comience un nuevo trabajo, lo que probablemente introducirá nuevos errores en el sistema.
- Si no se soluciona el problema, el centro de trabajo podría tener el mismo problema en el próximo ciclo, lo que requeriría más arreglos y trabajo.
- Los problemas solucionados deben ser parte de una base de conocimiento que pueda ser accedida globalmente. Esto permite que, en futuros incidentes, otros equipos puedan apoyarse en los aprendizajes pasados.
Continuar empujando la calidad en el origen
Inadvertidamente, podemos perpetuar sistemas de trabajo inseguros debido a la forma en que respondemos a accidentes e incidentes. En sistemas complejos, agregar más pasos de inspección y procesos de aprobación en realidad aumenta la probabilidad de fallas futuras.

La efectividad de los procesos de aprobación disminuye a medida que alejamos la toma de decisiones de donde se realiza el trabajo. Hacerlo no solo disminuye la calidad de las decisiones, sino que también aumenta nuestro tiempo de ciclo, lo que disminuye la fuerza de la retroalimentación entre causa y efecto, y reduce nuestra capacidad de aprender de los éxitos y fracasos.
La calidad no es una fase que forma parte del flujo de valor en un momento determinado, es una disciplina que debe extenderse a lo largo de todo el flujo de valor. Para mejorar la calidad:
- En los centros de trabajo se utilizan revisiones por pares de nuestros cambios propuestos para obtener la seguridad necesaria de que nuestros cambios funcionarán según lo diseñado.
- Automatizamos la mayor cantidad posible de control de calidad que generalmente realiza un departamento de calidad o seguridad de la información.
- En lugar que los desarrolladores necesiten solicitar o programar una prueba para que se ejecute, estas pruebas se pueden realizar a demanda (autoservicio), lo que permite a los desarrolladores probar rápidamente su propio código e incluso implementar esos cambios en la producción ellos mismos.
Al hacer esto, realmente hacemos de la calidad la responsabilidad de todos, en lugar que sea la responsabilidad exclusiva de un departamento separado. La seguridad de la información no es solo el trabajo de la Seguridad de la Información, así como la disponibilidad no es simplemente el trabajo de Operaciones.
Habilitar la optimización para los centros de trabajo posteriores
Lean define dos tipos de clientes para los que debemos diseñar: el cliente externo (que probablemente paga por el producto/servicio que brindamos) y el cliente interno (que recibe y procesa el trabajo inmediatamente después de nosotros).

En el flujo de valor de la tecnología, optimizamos para los centros de trabajo posteriores mediante el diseño para operaciones, donde los requisitos operativos no funcionales (por ejemplo, arquitectura, rendimiento, estabilidad, capacidad de prueba, configurabilidad y seguridad) tienen una prioridad tan alta como las características del usuario.
Según Lean, para lograr un flujo continuo de trabajo y con alta calidad, nuestro cliente más importante es nuestro siguiente paso. La optimización de nuestro trabajo para ellos requiere que tengamos empatía por sus problemas para identificar mejor los problemas de diseño que impiden un flujo rápido y suave.
Todos estos elementos que forman parte de los “Principios del feedback” buscan establecer un escenario de confianza que permita a los equipos mejorar el conocimiento de su entorno, aumentar la calidad y mejorar el flujo de entrega de valor. Todo lo anterior se soporta con buenos flujos de comunicación y modelos conversacionales.
Artículos relacionados
En SOAINT, comprendemos tus contextos organizacionales, con el fin de construir realidades tecnológicas encaminadas a tu desarrollo y crecimiento.
¡Confía en nosotros para desarrollar todo el potencial de tu empresa!


